Pairwise Comparison of two Proteins dataset#
In this example, you:
Create a proteins datasets from a Pandas data frame.
Evaluate quantitative values distribution and number of missing values per experiment.
Apply missing value imputation.
Perform pairwise comparative analysis using a t-test and fold-change rule.
Export results back to a Pandas data frame for further analysis.
First you can install the library if missing, using pip.
[2]:
# !pip install omicspylib
[3]:
import matplotlib.pyplot as plt
import pandas as pd
from omicspylib import ProteinsDataset, PairwiseComparisonTTestFC, __version__
from omicspylib.plots import plot_density, plot_missing_values, plot_volcano
print(f'omicspylib version: {__version__}')
omicspylib version: 0.1.0
Start with a tabular dataset containing only the protein identifier and the quantitative values per experiment. Additional annotation (e.g. protein names, gene names) can be stored elsewhere and merged back to the results in a later step.
[4]:
data = pd.read_csv('data/protein_dataset.tsv', sep='\t')
data.head(3)
[4]:
| protein_id | c1_rep1 | c1_rep2 | c1_rep3 | c1_rep4 | c1_rep5 | c2_rep1 | c2_rep2 | c2_rep3 | c2_rep4 | c2_rep5 | c3_rep1 | c3_rep2 | c3_rep3 | c3_rep4 | c3_rep5 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | p0 | 1748947.964 | 2655665.55 | 1812807.047 | 3179830.747 | 3002006.748 | 0.000 | 1357720.520 | 0.000 | 2087116.684 | 0.000 | 2558776.479 | 2655657.487 | 2115434.782 | 2889376.029 | 0.000 |
| 1 | p1 | 1689613.957 | 0.00 | 1953790.640 | 2447525.246 | 2877005.859 | 1438315.297 | 1198347.576 | 1864606.985 | 0.000 | 1414141.418 | 0.000 | 3070691.996 | 3149289.453 | 0.000 | 2264704.900 |
| 2 | p2 | 2053224.994 | 0.00 | 0.000 | 1729807.427 | 1307542.588 | 1062917.256 | 1466408.270 | 0.000 | 0.000 | 1461644.025 | 2538368.164 | 2136675.019 | 2565203.051 | 3772302.809 | 2793083.403 |
Create your dataset object by specifying the column name with the protein ids and the experimental condition groups.
[5]:
conditions = {
'c1': [f'c1_rep{i+1}' for i in range(5)],
'c2': [f'c2_rep{i+1}' for i in range(5)],
'c3': [f'c3_rep{i+1}' for i in range(5)],
}
dataset = ProteinsDataset.from_df(data, id_col='protein_id', conditions=conditions)
dataset.describe()
[5]:
{'n_conditions_total': 3,
'n_records_total': 100,
'n_experiments_total': 15,
'statistics_per_condition': [{'name': 'c1',
'n_experiments': 5,
'n_records': 100,
'experiment_names': ['c1_rep1', 'c1_rep2', 'c1_rep3', 'c1_rep4', 'c1_rep5'],
'n_records_per_experiment': [74, 73, 67, 71, 76]},
{'name': 'c2',
'n_experiments': 5,
'n_records': 100,
'experiment_names': ['c2_rep1', 'c2_rep2', 'c2_rep3', 'c2_rep4', 'c2_rep5'],
'n_records_per_experiment': [71, 70, 67, 68, 80]},
{'name': 'c3',
'n_experiments': 5,
'n_records': 100,
'experiment_names': ['c3_rep1', 'c3_rep2', 'c3_rep3', 'c3_rep4', 'c3_rep5'],
'n_records_per_experiment': [80, 73, 78, 74, 80]}]}
Perform basic exploratory analysis by passing the dataset to the relevant plotting functions. For example, you can plot the quantitative value distribution (raw or log transformed), or count the number of missing values per experiment. The output of plotting functions is a matplotlib’s plt.Axes object. So, you can use standard matplotlib syntax to stylize it or combine with other plots.
[6]:
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
plot_density(dataset=dataset.log2_transform(), ax=ax[0])
plot_missing_values(dataset=dataset, ax=ax[1])
plt.suptitle('Dataset properties evaluation')
plt.tight_layout()
plt.show()

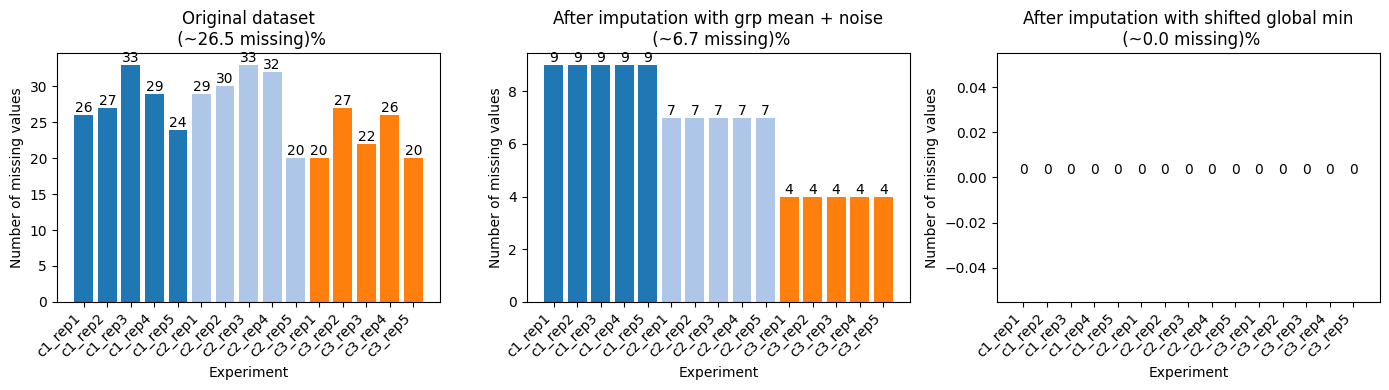
Optionally, you can impute the missing values. Each imputation/transformation step returns a new ProteinsDataset object that you can keep modifying.
[7]:
# perform missing value imputation on log2 transformed data
l2_dset = dataset.log2_transform()
# for each group impute each protein with the with-in group mean value + some random noise
grp_mean_l2_imputed_dset = l2_dset.impute(method='group row mean', random_noise=True)
# impute the rest missing values by the global min of the dataset shifted by a fixed number
l2_imputed_dset = grp_mean_l2_imputed_dset.impute(method='global min', shift=1.0)
fig, ax = plt.subplots(1, 3, figsize=(14, 4))
plot_missing_values(dataset=l2_dset, ax=ax[0], title='Original dataset\n')
plot_missing_values(dataset=grp_mean_l2_imputed_dset, ax=ax[1], title='After imputation with grp mean + noise\n')
plot_missing_values(dataset=l2_imputed_dset, ax=ax[2], title='After imputation with shifted global min\n')
plt.tight_layout()
plt.show()
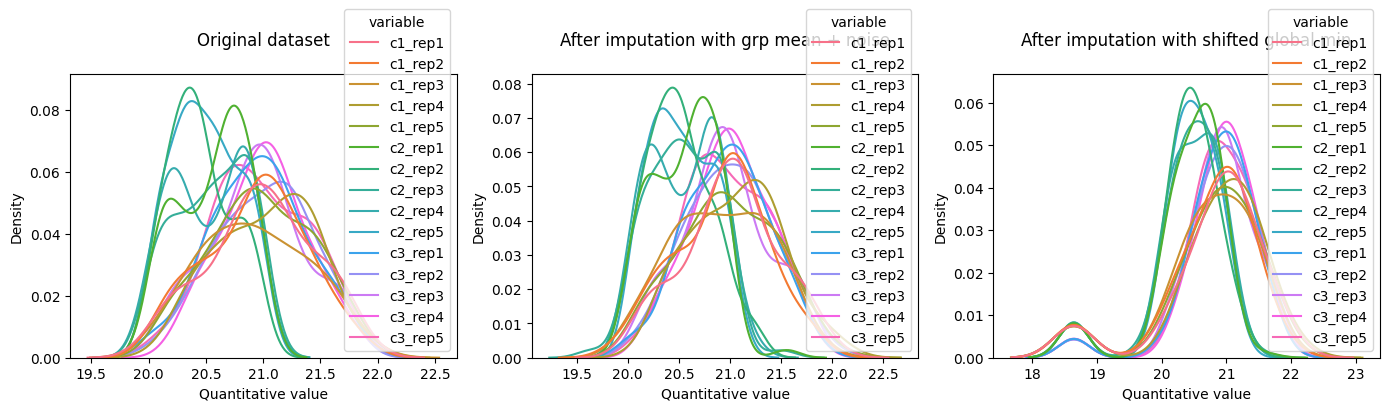
fig, ax = plt.subplots(1, 3, figsize=(14, 4))
plot_density(dataset=l2_dset, ax=ax[0], title='Original dataset\n')
plot_density(dataset=grp_mean_l2_imputed_dset, ax=ax[1], title='After imputation with grp mean + noise\n')
plot_density(dataset=l2_imputed_dset, ax=ax[2], title='After imputation with shifted global min\n')
plt.tight_layout()
plt.show()
The PairwiseComparisonTTestFC class, will perform a t-test and apply a fold change rule, to identify differentially abundant records. By default, t-test uses log2 transformed values, whereas fold change calculation, uses raw values. The compare comparison results is a Pandas data frame, with the protein id, in this example, stored in the row index. You can use the index to merge the comparison results back to the table with the input values.
[8]:
# back transform imputed dataset to the original scale, before starting the pairwise comparison
imputed_dataset = grp_mean_l2_imputed_dset.log2_backtransform()
comparison = PairwiseComparisonTTestFC(imputed_dataset, condition_a='c1', condition_b='c2', )
ttest_results = comparison.eval(pval_adj_method='fdr_bh')
ttest_results.head(3)
[8]:
| p-value | t-statistic | adj-p-value | fold change | log2 fold change | |
|---|---|---|---|---|---|
| protein_id | |||||
| p0 | 0.061305 | 2.175349 | 0.101390 | 1.427599 | 0.513591 |
| p1 | 0.011738 | 3.247891 | 0.025248 | 1.485676 | 0.571119 |
| p10 | 0.873161 | 0.164837 | 0.883434 | 1.015143 | 0.021683 |
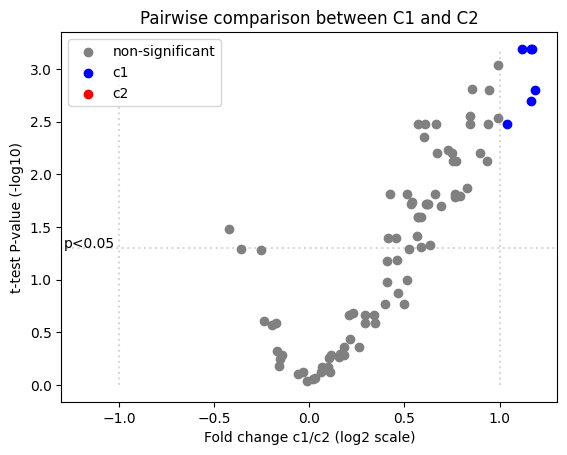
The result of PairwiseComparisonTTestFC comparison can be passed directly to plot_volcano function, to create a volcano plot. Use standard matplotlib syntax to stylize the plot.
[9]:
ax = plot_volcano(ttest_results, pval_col='adj-p-value', fc_col='fold change', condition_a='c1', condition_b='c2')
ax.set_title('Pairwise comparison between C1 and C2')
plt.show()
Convert a dataset to a Pandas data frame, using the to_table method. The record id is stored as row index, and you can merge comparison results to that table via this relationship.
[10]:
output_df = imputed_dataset.to_table()
output_df = output_df.merge(ttest_results, left_index=True, right_index=True, how='outer')
output_df.head(4)
# output_df.to_csv('dest_dir/pairwise_comparison.csv', sep='\t', index=True) # standard pandas flow
[10]:
| c1_rep1 | c1_rep2 | c1_rep3 | c1_rep4 | c1_rep5 | c2_rep1 | c2_rep2 | c2_rep3 | c2_rep4 | c2_rep5 | c3_rep1 | c3_rep2 | c3_rep3 | c3_rep4 | c3_rep5 | p-value | t-statistic | adj-p-value | fold change | log2 fold change | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| protein_id | ||||||||||||||||||||
| p0 | 1748947.964 | 2.655666e+06 | 1812807.047 | 3.179831e+06 | 3.002007e+06 | 2.010294e+06 | 1.357721e+06 | 1.365435e+06 | 2.087117e+06 | 1.864825e+06 | 2.558776e+06 | 2.655657e+06 | 2115434.782 | 2.889376e+06 | 2.442846e+06 | 0.061305 | 2.175349 | 0.101390 | 1.427599 | 0.513591 |
| p1 | 1689613.957 | 1.903632e+06 | 1953790.640 | 2.447525e+06 | 2.877006e+06 | 1.438315e+06 | 1.198348e+06 | 1.864607e+06 | 1.402181e+06 | 1.414141e+06 | 2.855995e+06 | 3.070692e+06 | 3149289.453 | 2.748164e+06 | 2.264705e+06 | 0.011738 | 3.247891 | 0.025248 | 1.485676 | 0.571119 |
| p10 | 1757091.693 | 1.536626e+06 | 1149483.961 | 1.600724e+06 | 1.701100e+06 | 2.052588e+06 | 1.502641e+06 | 1.374370e+06 | 1.297363e+06 | 1.402528e+06 | 2.571566e+06 | 4.319021e+06 | 3648111.452 | 2.959571e+06 | 3.233381e+06 | 0.873161 | 0.164837 | 0.883434 | 1.015143 | 0.021683 |
| p11 | 2596847.916 | 2.592526e+06 | 2686205.008 | 3.671799e+06 | 2.684965e+06 | 1.461644e+06 | 1.528603e+06 | 1.837380e+06 | 1.226513e+06 | 1.329203e+06 | 1.624380e+06 | 1.982778e+06 | 1660887.127 | 1.920664e+06 | 1.852346e+06 | 0.000128 | 6.873605 | 0.001577 | 1.927629 | 0.946827 |